
너무 공감이 가는 자료라서, 읽어보시길 바랍니다. 1. 경험이 쌓여야 좋은 판단을 할수 있음. 2. 최종 사용자 배포 전 흔히 저지르는 실수들: 이상적인 해피케이스에만 집중: 부족한 사용자 수용 테스트(UAT): 불완전한 테스트 범위: 비현실적인 테스트 데이터: 환경 차이: 통합 테스트 부족: 비기능적 테스트 생략: 3. 기타 사례:

많은 기업의 시니어 레벨 육성을 위한 아키텍처 설계 요구에 부응하기 위해, 또한 대용량 트래픽을 다루는 국내 프론트엔드 모니터링 1위 솔루션 IMQA를 다루면서, 현업에 맞는 대규모 과정으로 업데이트를 했습니다. (같이 일한 IMQA 식구들의 노하우가 너무 컸습니다. ) 프레임워크 내부를 설명하는 전통적인 패턴과 최신 트랜드를 반영한 패턴들을 조화롭게 설명하였고 , 실제 사용되는 Use Case들 기반으로 많은 부분들을 […]

소프트웨어 아키텍트의 길은 멀고 험난합니다. 그 와중에 조금이나마 아키텍트를 꿈꾸거나, 진입하시는 분들을 위한 과정을 진행하고 있습니다. 이미 다양한 대기업에서 강의를 했습니다. 수업의 커리큘럼은 다음과 같습니다. 관심있는 기업 교육자 담당자 분들은 연락을 주시면 됩니다. 시간당 25만원이 아니면 강의를 하지 않습니다. 시간당 20만원의 요청이 제법있는데, 안 하기로 했습니다. 다만 수도권이 아닌 지방이라면 지식 공유를 위해 훨씬 저렴하게 […]

저는 K-Devcon 2025 커뮤니티를 통해 비벤더 기술 중심 세미나에 참석하게 되어 기쁩니다. 이 발표에서는 대규모 데이터를 효과적으로 추정하는 기법에 대해 다룰 것입니다. 실제 강의에서 발표된 내용을 요약하여, 다양한 알고리즘(예: Bloom Filter, Count-Min Sketch 등)을 소개할 예정입니다. 참석자들이 부담 없이 편하게 들어주시기를 바랍니다. 최대한 핵심을 전달하도록 노력하겠습니다.

베타리더 모집 링크 https://docs.google.com/forms/d/e/1FAIpQLSdWIAzkEs9E2SRzHS_hfttCLUPm9JAb5hkwdmPx1e2iFx-2hg/viewform 누군가는 꼭 번역했어야 할, 그런 책이었습니다. 『Pattern-Oriented Software Architecture』는 GoF의 디자인 패턴과 함께 소프트웨어 설계 패턴의 양대 산맥이라 불릴 만큼 깊은 영향을 끼친 명서입니다. 객체지향의 미시적 설계에 초점을 맞춘 GoF가 있었다면, POSA는 시스템 수준의 구조적 사고와 아키텍처적 시야를 열어준 책이었습니다. 약 15년 전, 이 책의 번역 작업에 참여했던 저는 최근 다시 […]

패턴 I 회에서는 아키텍처 시각화 패턴의 전체적인 구조와 구성되는 패턴들의 종류들을 간단히 소개하고, 아키텍처 시각화를 하기 전에 소프트웨어 시스템을 분석하기 위한 기본 요소들인 Domain Level Classifier Pattern과 Class Dependency Classifier Pattern에 대해서 살펴보았다.
2회에서는 시간에는 소프트웨어 시스템의 아키텍처 분석에 기본이 되는 다양한 Metric에 대한 설명을 올렸다.
이번 3회에서는 의존성을 관리하는 시각화 지표를 설명한다.

새로운 오프라인 강의가 준비되었습니다. Cloud (MSA) 패턴 에 관한 120페이지 분량의 강의가 완성되었습니다. 하지만 요즘 현 시대에 맞는 아키텍팅을 준비하기 위해 최신 패턴들을 정리했습니다. 주로 참고한 자료들은 아래에 있습니다. 거의 2주간 정리를 진행했으며, 알고 있는 패턴도 있었지만, 나름 깨달음을 많이 주는 패턴 들도 있었습니다. 패턴 목록 참고 아키텍처 시리즈 정리한 패턴 상황.. 관련된 강의 의뢰나 […]

이번 시간은 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 마지막 시간으로 Geo Hash를 이용하여 아키텍처 개선하기에 대해 다루겠습니다.

이 글은 Kousik Nath의 System Design: Design a Geo-Spatial index for real-time location search을 번역한 글로, 모든 저작권은 원저작자에 있습니다. 최대한 원문을 살리려 했으나, 이해를 돕기 위해 의역과 역주를 사용한 곳도 있습니다.
수정할 부분이 있다면 indigogurur골뱅이gmail.com으로 남겨주시길 바랍니다.
2부는 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 두 번째 시간으로 샤딩으로 아키텍처 개선하기에 대해 다루었습니다.
- 개요 및 아키텍처
- 샤딩으로 아키텍처 개선하기
- Geo Hash를 이용하여 아키텍처 개선하기
소개
우리는 실생활에서 항상 실시간 위치 검색 서비스를 사용합니다. 음식 주문 앱이나 주문형 택시 예약 서비스는 요즘 어디서나 볼 수 있죠. 이 글의 목적은 실생활에서 지리 공간 인덱스(Geo-spatial Index)에 대한 백엔드 인프라를 설계하는 방법을 살펴보는 것입니다.
지난 1편에서는 로드밸런서와 캐시를 이용하여 부하를 배분 및 감소하는 전통적인 아키텍처를 설명했습니다. 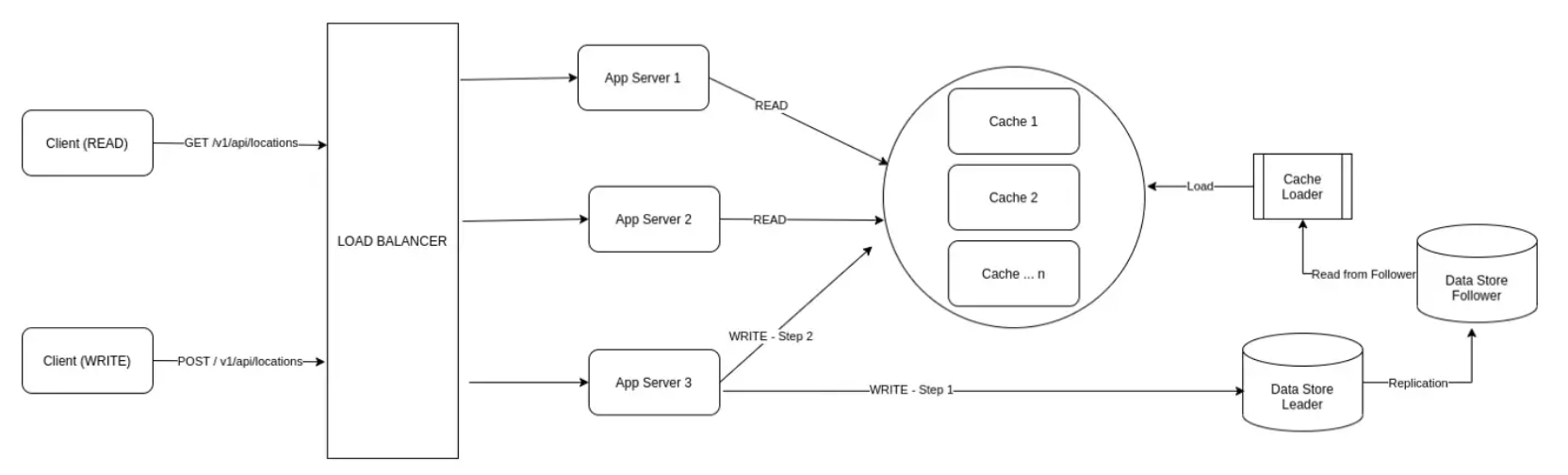
이번 시간에는 위 그림에서 더 개선된 아키텍처 접근법을 공유합니다. 더 나은 방법으로 캐시를 분할하는 방법을 알아보도록 하겠습니다.
계속 읽기
이 글은 Kousik Nath의 System Design: Design a Geo-Spatial index for real-time location search을 번역한 글로, 모든 저작권은 원저작자에 있습니다. 최대한 원문을 살리려 했으나, 이해를 돕기 위해 의역과 역주를 사용한 곳도 있습니다. 수정할 부분이 있다면 indigoguru@gmail.com으로 남겨주시길 바랍니다. 이번 시간은 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 첫 번째 시간으로 개요 […]

지난해 다양한 소프트웨어 아키텍팅 강의를 진행해 왔습니다. 아키텍처 설계 및 평가 기법, 그리고 부하테스트/ 성능 최적화에 대한 강의가 주를 이루었습니다. 아키텍처 설계 프로세스는 말그대로 진행은 하면 되지만, 결국 많은 설계 기법을 알지 못하면 좋은 설계를 하지 못하는 상황이 빈번하게 발생했습니다. 2022년에 다음과 같은 강좌 들을 진행했습니다. 강의를 하다보면서, 아직 많은 교재들이 디자인패턴에 지식이 머물러있고, 몇몇 […]
