트위터는 왜 두번이나 모니터링 시스템을 직접 개발 하였을까요? Monitorama 에서 발표한 Building Twitter Next-Gen Alerting System과 여러 컨퍼러스에서 발표한 내용을 정리해서 공유해 드리고자 합니다.
Twitter 모니터링 초창기 시스템 아키텍처

첫 모니터링 솔루션은 위와 같이 아키텍처를 수립하였습니다. (현재 오픈소스 솔루션과 유사하죠) 1.0 시스템은 다음과 같은 컴포넌트로 구성되어 있습니다. (트위터의 모니터링 시스템이 오픈소스로 공개되지 않아서, 전적으로 발표자료에 의존해 설명이 구체적이지 않습니다. )
- Agent – 데이터를 수집하는 Agent로 시스템 성능에 필요한 여러 지표를 수집.
- Collector & Storage API – 수집부에서 데이터를 모아 Storage API 를 통해 Time Series Database( Manhattan으로 추정)에 저장하고, 그정보를 Cassandra에 저장.
- Monitoring – Query 엔진으로 데이터를 긁어와 여러 지표를 모니터링.
- Dashboard – Alert 과 Dashboard 를 쉽게 구성할수 있는 Config, DSL을 제공.
- Ad Hoc Queries – 상황에 따라 적합한 쿼리를 던질수 있음.
트위터는 왜 모니터링 2.0 시스템을 만들어야 했나?
하지만 트위터의 급격한 성장으로 인해, 위 아키텍처로는 더 이상 모니터링을 할수 없는 상황이 되었습니다.
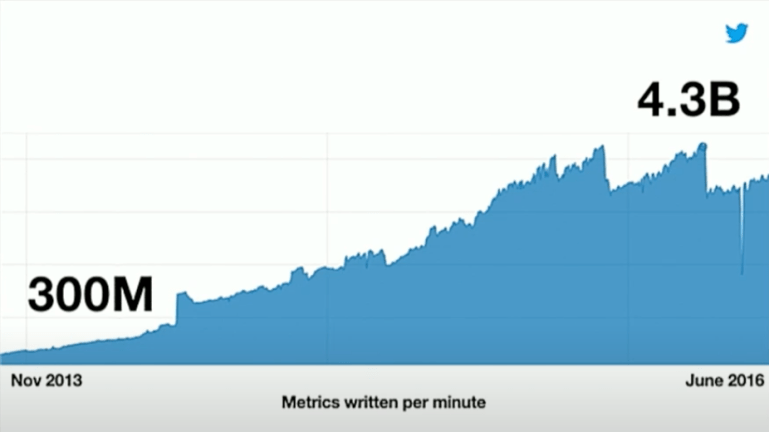
- 1분당 수집되는 메트릭이 3년 만에 3억개(300M)-> 14배로 43억개(4.3B)으로 증가.
- 발생하는 알럿의 증가 – 1분당 2500개 -> 1분당 3만개로 증가.