
너무 공감이 가는 자료라서, 읽어보시길 바랍니다. 1. 경험이 쌓여야 좋은 판단을 할수 있음. 2. 최종 사용자 배포 전 흔히 저지르는 실수들: 이상적인 해피케이스에만 집중: 부족한 사용자 수용 테스트(UAT): 불완전한 테스트 범위: 비현실적인 테스트 데이터: 환경 차이: 통합 테스트 부족: 비기능적 테스트 생략: 3. 기타 사례:

많은 기업의 시니어 레벨 육성을 위한 아키텍처 설계 요구에 부응하기 위해, 또한 대용량 트래픽을 다루는 국내 프론트엔드 모니터링 1위 솔루션 IMQA를 다루면서, 현업에 맞는 대규모 과정으로 업데이트를 했습니다. (같이 일한 IMQA 식구들의 노하우가 너무 컸습니다. ) 프레임워크 내부를 설명하는 전통적인 패턴과 최신 트랜드를 반영한 패턴들을 조화롭게 설명하였고 , 실제 사용되는 Use Case들 기반으로 많은 부분들을 […]

이 글은 Kousik Nath의 System Design: Design a Geo-Spatial index for real-time location search을 번역한 글로, 모든 저작권은 원저작자에 있습니다. 최대한 원문을 살리려 했으나, 이해를 돕기 위해 의역과 역주를 사용한 곳도 있습니다. 수정할 부분이 있다면 indigoguru@gmail.com으로 남겨주시길 바랍니다. 이번 시간은 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 첫 번째 시간으로 개요 […]

지난해 다양한 소프트웨어 아키텍팅 강의를 진행해 왔습니다. 아키텍처 설계 및 평가 기법, 그리고 부하테스트/ 성능 최적화에 대한 강의가 주를 이루었습니다. 아키텍처 설계 프로세스는 말그대로 진행은 하면 되지만, 결국 많은 설계 기법을 알지 못하면 좋은 설계를 하지 못하는 상황이 빈번하게 발생했습니다. 2022년에 다음과 같은 강좌 들을 진행했습니다. 강의를 하다보면서, 아직 많은 교재들이 디자인패턴에 지식이 머물러있고, 몇몇 […]

맥을 쓰다보면 Parallel Desktop , Clean My Mac 같은 솔루션들이 끊임없이 매출을 창출하기 위해 버전을 관리하는 방법들을 내놓고 있다. 물론 새버전이 나올때마다 새롭게 사게해서, 짜증이긴 하지만.. 그 들도 먹고 살아야 하니 어쩔수없다. 그 만큼 가치가 있다면 계속 돈주고 사야지. 그럼 솔루션 업체 입장에서는 어떻게 해야 저항없이 고객들이 새 버전으로 솔루션을 업그레이드 할수있게 만들 수 있을가? […]

무려 3년이 다 되어가지만, 일전에 SaaSTR이라는 컨퍼런스에 다녀왔다. (좋은 행사에 보내주신, WhaTap 에 이동인 대표님에게 감사를 드린다) AppDynamics가 Cisco에 4조에 인수된 사건과 발생하였고, SaaS에서 내놓으라는 회사에서 자신의 노하우와 여러 기반 기술을 공유한 행사였다. 여기서 크게 관심을 가진 세션이 있었는데 CPO가 무엇을해야 되는지에 대한 세션이었다.

CPO(최고 제품 개발자) 또는 VPP (VP of Product)가 해야 되는 일
- 물건을 잘 파는 거, 향후 전략, 마켓팅과 연합.
- 일반 고객 / 중요 고객 / 엔지니어 팀과 이야기 하면서 방향을 잡아가는 것.
- 지휘자 / 커뮤니케이터 / 오케스트레이션, 오가나이제이션
- 팀간에 ceo가 vision을 실행한다면 그걸 하게 만들어야 되는 역할.
CPO(VPP)와 프로덕트 관리자와 다른 것은 무엇인가요?
- 접점이 달라진다. 팀원을 이끄는게 아니라, 고객과 이야기 하고 고객이 원하는 product으로 갈수 있게 이끌어야 한다.
leadership이 달라진다. pm은 엔지니터링 팀을 이끌고 잘 돌아가는게 하는게 목적. - CPO(VPP)는 정말 다양한 백그라운드를 가지고 있다.
– 디자이너 출신: 고객의 경험을 중심. 어떠한 성격을 가지는지. 어떻게 고객과 점접을 가지고 이야기 하는지.
– 엔지니어 출신: 실현 가능한지, Scope은 얼마인지에 집중이 필요하다.
Cx 레벨간의 차이는 무엇인가요?
- CEO는 비전을 제시한다
- CPO는 사용자가 어떠한 느낌을 가질지, 어떠한 기능을 제공할지 고민을 해야 한다.
- CTO는 자동차의 엔진을 잘 만들어야 한다.
CPO가 해야 할일을 구체적으로 알려주세요.
- 고객과의 접점을 늘리고, 어떠한 제품과 기능을 제공해야 하는지, 많은 이야기를 해야 한다.
- 유저 스토리를 만들고 왜 사용하고, 어떻게 진행하고 등에 대해서 끊임없이 이끌어야 한다.
- engineer , marketer, customer 간에 조율하고 이끌어야 한다.
- context switching 을 잘해야 한다. 7일에 7개의 언어를 배우듯이 여기 저기 왔다 갔다 잘해야 한다. 상황에 맞게 변신하는게 매우 중요하다.

싸움은 가능한 피해야 하나, 결국 제한된 자원에서 소수의 승자만 존재한다면, 어쩔수 없이 싸움(경쟁)을 해야 한다.
싸우지 않고 이기는 것이 가장 최상이다. 라는 말은 있으나 실제 어떻게 하면 구체적으로 이걸 하는지 실행 방법에 대해서 구체적으로 나온 글등은 찾기 어려웠다. 요즘 당하고 있는데. 역시 고수는 다르다는 것을 깨닫고 있다.
보통 고수들의 전략을 보면 다음과 같다.
- 절대 자신이 직접 싸우지 않는다.
- 자신의 의견을 대신해서 잘 내세울 여러 대리자들을 만든다.
- 대리자들을 만들기 위해서는 당연히 보상이 필요하다. (이익을 확실히 보장하거나, 한 자리를 주겠다거나, 넌 정의를 지키는 사도야 그러니 꼭 니가 나서야해! 그럴 힘은 너만 있어.. 등.. )
- 그리고 싸우고자 하는 상대의 부정적인 정보를 계속 전달한다.
- 이 대리자들은 부정적인 시각으로 벌써 상대방을 바라보기 때문에, 직접 만나도 의심의 눈초리로 바라본다. 대부분 설득이 되지 않는다.
- 결국 대리자와 당사자는 피터지게 싸운다.
- 대리자가 이기면, 자신의 영향력을 발휘해 계속 잘 관리하면서 같이 이익을 공유한다.
- 대리자가 진다면, 결국 자기는 크게 상처를 입지 않고, 결국 싸움판이 벌어졌기 때문에 싸운 당사자들만 피를 보며 평판이 나빠진다.
그럼 여기서 만약 내가 당하는 피해자라면 해야 될 방어 전략은 무엇이 있을까?
CPO는 제품의 향후 마일스톤을 결정하고, 어떠한 가치및 기능들을 전달할지 결정하는 역할이다. 개발자에게는 제품/상품이라는 개념이 다소 생소할수 있겠지만, 결국 우리가 만드는 SW들은 고객들에게 하나의 상품이다. 고객의 입장에서 매력적인 / 또 실제 팔릴수 있는 상품을 만들수 있게 제품 전반에 지휘권을 가지고 있는 자다.

트위터는 왜 두번이나 모니터링 시스템을 직접 개발 하였을까요? Monitorama 에서 발표한 Building Twitter Next-Gen Alerting System과 여러 컨퍼러스에서 발표한 내용을 정리해서 공유해 드리고자 합니다.
Twitter 모니터링 초창기 시스템 아키텍처

첫 모니터링 솔루션은 위와 같이 아키텍처를 수립하였습니다. (현재 오픈소스 솔루션과 유사하죠) 1.0 시스템은 다음과 같은 컴포넌트로 구성되어 있습니다. (트위터의 모니터링 시스템이 오픈소스로 공개되지 않아서, 전적으로 발표자료에 의존해 설명이 구체적이지 않습니다. )
- Agent – 데이터를 수집하는 Agent로 시스템 성능에 필요한 여러 지표를 수집.
- Collector & Storage API – 수집부에서 데이터를 모아 Storage API 를 통해 Time Series Database( Manhattan으로 추정)에 저장하고, 그정보를 Cassandra에 저장.
- Monitoring – Query 엔진으로 데이터를 긁어와 여러 지표를 모니터링.
- Dashboard – Alert 과 Dashboard 를 쉽게 구성할수 있는 Config, DSL을 제공.
- Ad Hoc Queries – 상황에 따라 적합한 쿼리를 던질수 있음.
트위터는 왜 모니터링 2.0 시스템을 만들어야 했나?
하지만 트위터의 급격한 성장으로 인해, 위 아키텍처로는 더 이상 모니터링을 할수 없는 상황이 되었습니다.
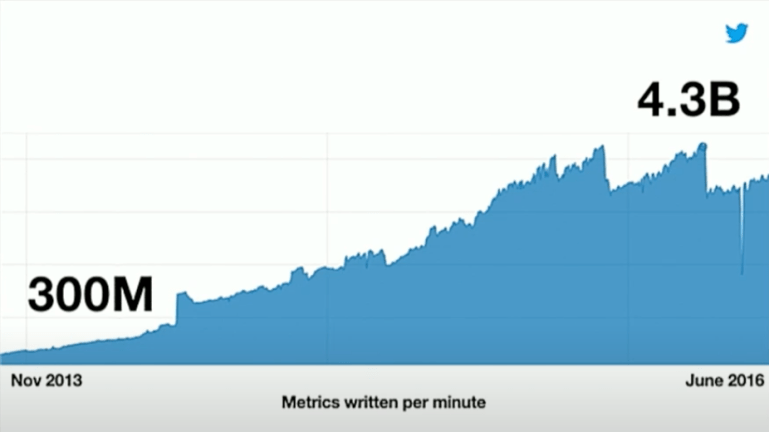
- 1분당 수집되는 메트릭이 3년 만에 3억개(300M)-> 14배로 43억개(4.3B)으로 증가.
- 발생하는 알럿의 증가 – 1분당 2500개 -> 1분당 3만개로 증가.
mongodb가 혜성처럼 등장해 많은 사랑을 받은 이유가 여러가지 있다. 가장 큰 덕은 모바일의 폭발적인 성장이지만, 개발자에게는..
- auto-sharding
- schemaless + json 데이터 저장
- 자체적으로 가지고 있는 master-slave high availability 기능
정도 되지 않을까 생각한다.
sharding이라는 것은 꽤 귀찮은 작업으로 어떻게 데이터를 분배해야 할지 많은 고민을 해야 되는데, 굳이 크게 고민하지 않고 auto-sharding을 쓸수 있는 적당한 규모의 프로젝트라면 마다할 필요가 없다.
또한 High Availiability를 자체적으로 지원을 하는데
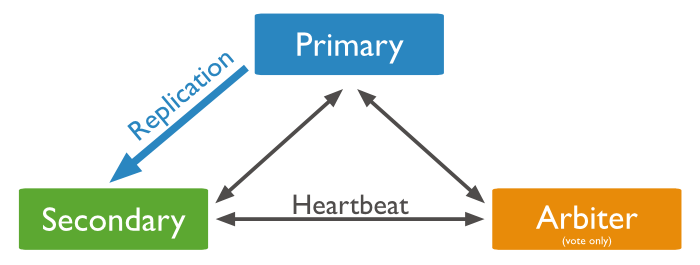 1) 별도의 watcher인 arbiter 를 셋업하여 master-slave를 감시하는 방법
1) 별도의 watcher인 arbiter 를 셋업하여 master-slave를 감시하는 방법
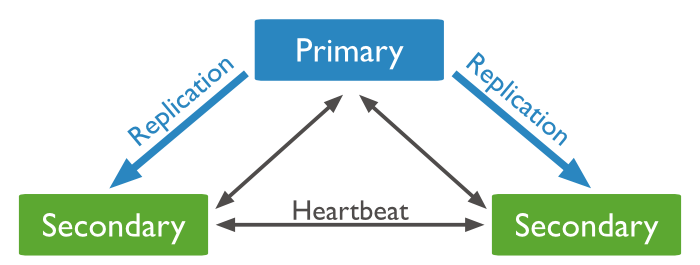 2) watcher없이 master-slave가 서로 heartbeat 메세지를 보내고 문제를 감지해 failover를 처리하는 방법
2) watcher없이 master-slave가 서로 heartbeat 메세지를 보내고 문제를 감지해 failover를 처리하는 방법
이렇게 두가지를 지원한다. 개발자에게는 야호하고 소리를 지를수 있는 좋은기능! (단 죽은 master를 어떻게 살리지는 개발자 여러분의 몫 – 좋은 방법이 있으면 공유를…)
