etcd를 이용한 high availability 확보 방안
mongodb가 혜성처럼 등장해 많은 사랑을 받은 이유가 여러가지 있다. 가장 큰 덕은 모바일의 폭발적인 성장이지만, 개발자에게는..
- auto-sharding
- schemaless + json 데이터 저장
- 자체적으로 가지고 있는 master-slave high availability 기능
정도 되지 않을까 생각한다.
sharding이라는 것은 꽤 귀찮은 작업으로 어떻게 데이터를 분배해야 할지 많은 고민을 해야 되는데, 굳이 크게 고민하지 않고 auto-sharding을 쓸수 있는 적당한 규모의 프로젝트라면 마다할 필요가 없다.
또한 High Availiability를 자체적으로 지원을 하는데
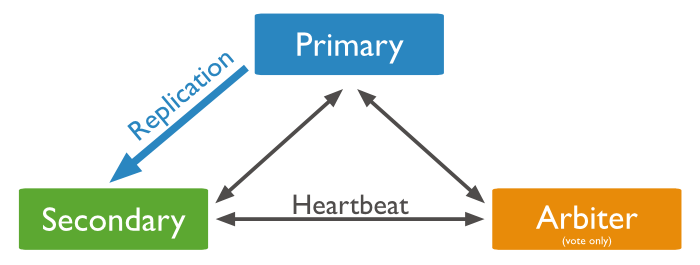 1) 별도의 watcher인 arbiter 를 셋업하여 master-slave를 감시하는 방법
1) 별도의 watcher인 arbiter 를 셋업하여 master-slave를 감시하는 방법
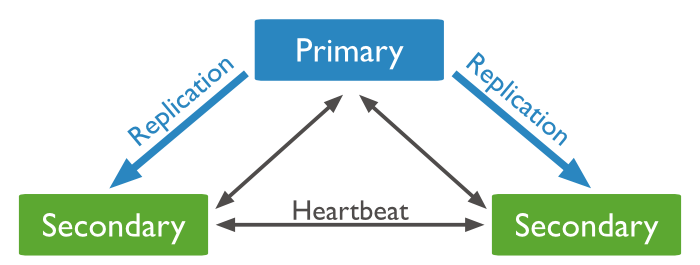 2) watcher없이 master-slave가 서로 heartbeat 메세지를 보내고 문제를 감지해 failover를 처리하는 방법
2) watcher없이 master-slave가 서로 heartbeat 메세지를 보내고 문제를 감지해 failover를 처리하는 방법
이렇게 두가지를 지원한다. 개발자에게는 야호하고 소리를 지를수 있는 좋은기능! (단 죽은 master를 어떻게 살리지는 개발자 여러분의 몫 – 좋은 방법이 있으면 공유를…)
문제는 HA를 자체적으로 지원하지 않는 DB들..
문제는 오픈소스 DBMS에서 master-slave간에 뾰족한 high availability를 지원하지 않는 경우이다.
apache zookeeper 를 통해 high availiability를 확보하는 방안들이 여기 저기 공유되고 있으나 zookeeper는 구현시 여러가지 불편함이 있다. 트리구조로 관리되고 일회성 트리거라는 부분이 꽤 귀찮음을 유발한다.
이에 대해 많은 고민을 하다가 작년에 김현종님에게 etcd라는 것을 소개 받았다.
도대체 etcd가 무엇인가 고민하게 되고? etcd의 정의를 보면. 응 이게 watcher랑 무슨 관계이지? 라고 생각하게 되었다.
etcd의 정의
etcd는 go언어와 Raft프레임워크 이용해 작성된 오픈소스 key-value 저장소로 대규모 Docker 클러스터링에 있어서 컨테이너들을 유기적으로 연동시키고 억세스하기 위한 세련된 아키텍처를 제공하는 녀석이다.
현종님께서 etcd로 high availability를 구현하는 방법을 보여주셨는데, mongodb의 arbiter처럼 별도로 독립적인 서버를 설치해 주기적으로 heartbeat 또는 ping/pong등 상황에 맞는 전략을 사용해 , 문제시 failover를 해결하는 방법이었다.

틀렸다는게 아님. 이것도 좋은 방안이다 단지 다른 옵션이 있을 뿐! 때로는 심플한게 정신 건강에 좋다고 생각한다. etcd는 restful api로 쉽게 key/value에 접근할수 있고 더불어 보안관련 기능도 제공하고 있어서 etcd 하나만으로도 쉽게 restful key/value 저장소로 사용할수 있다.
계속 생기는 이상한 의문..
그런데 etcd를 보면서 계속 의문점이 생겼다. consequence를 보장하는 raft 알고리즘이라는 딱 버텨있고, 거기다가 master-slave에 준하는 leader-follower구조를 가질수 있게 cluster를 지원하고 있어서, 뭔가 다르게 구현하는 방법이 있다고 생각이 들었다.
mongodb에서 ha를 제공하는 방법중에서 별도의 서버 arbiter 없이 개별 노드들끼리 heartbeat 메세지를 보내며 처리하는 것과 유사한 형태로 처리하는 방법이 없을까? 고민끝에 여러 생각을 다하게 되었다.
mongodb에서 최신 oplog 를 가진 slave를 master로 올리거나나 riak/ cassandra에서 하는 versioning을 통해 최신의 데이터를 판단하는 방법이 있다.
그런데 고민을 해보니 정석이라고 할수 있는 etcd cluster를 구성하고 제공하는 raft의 기능을 그대로 이용해서, 빈번하게 leader쪽에 데이터를 보내고 follower들이 수신하여 versioning을 통해 충돌시 leader 후보군을 선정하는 방식을 생각할수 있다. (위 mongodb 2번째 방법과 유사)
etcd 의 raft 알고리즘을 그림으로 설명한 것이 있는데, 가장 직관적인 자료이다. 보면 볼수록 mongodb의 oplog가 생각난다.. etcd cluster를 setup한 이후 db의 log 정보를 leader에 전달한다면 비슷하게 구현이 가능하다. 아마 이 방법이 정식일 것으로 판단이 된다. leader / follower의 정보는 api를 통해 얻어오는게 가능하다.
하지만 빈번하게 consensus를 맞추기 위해 서로 끊임없이 메세지를 보낸다는 것이 그리고 셋팅부터 머리가 지근 지근 하다.
etcd의 TTL parameter와 prevExist를 이용해 leader(master)를 선정하는 방법.
무언가 구현하기 쉽고 더 간단한 방법, 간단한 방법.. 코딩이 귀찮아서..
게속 파고 파다 보니 좋은 자료(High Availability for PostgreSQL, Batteries Not Included)를 찾았다. etcd의 prevExist=false와 TTL을 활용해 leader key를 서로 set하도록 경쟁(race)을 통해 failover를 유지하는 방법이다. 간단하면서도 쓸만한 방법이라고 판단이 든다. 이 방법에 대한 diagram은 여기에 있다. python으로 돌아가는 sample code 도 있으니 참고하시길 바란다.
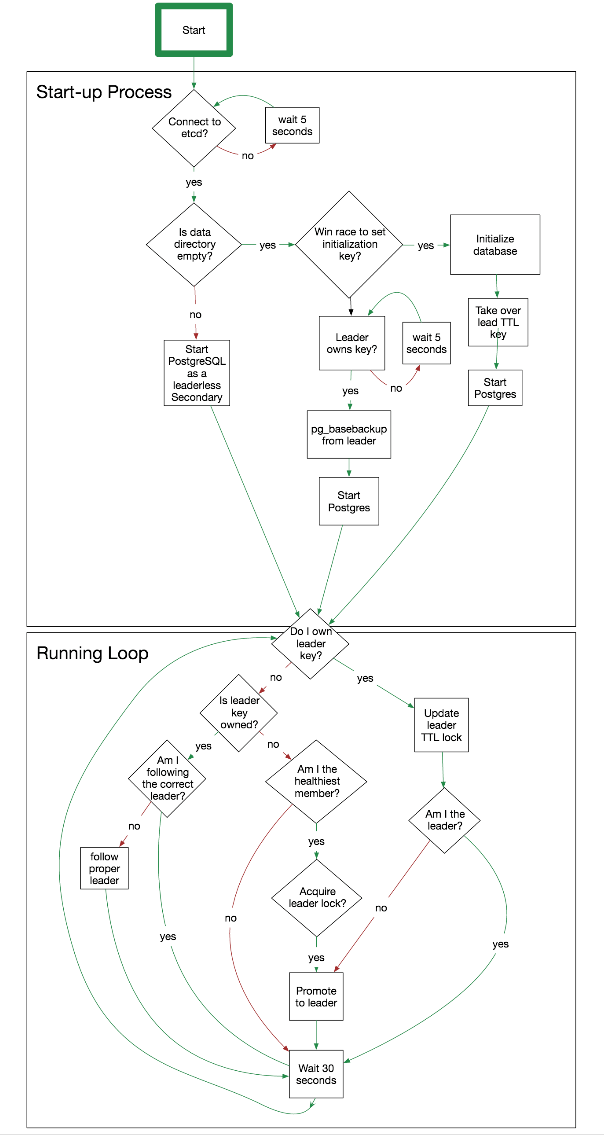
좋은 아이디어와 코드, 다이어그램을 공유해 주신 christopher winslett님에게 감사를 표하며 그가 공유한 다이어그램을 올린다.
여유가 되시면 mongodb의 oplog와 같이 구현하는 방법도 재미날듯 하다!.
정말? @#$@$!@$!@
참고 링크
- https://github.com/compose/governor
- https://www.compose.io/articles/high-availability-for-postgresql-batteries-not-included/
- https://github.com/coreos/etcd/blob/master/Documentation/clustering.md#static
- https://coreos.com/etcd/docs/0.4.7/etcd-api/
