클라우드를 도입한다면, 꼭 알아야 하는 것들.
클라우드 꼭 해야 하나?
클라우드 바람이 불고 있다. 개발자나 DBA 입장에서는 서버를 빌려쓰는 것으로 이해할 수 있지만, 전통적인 시스템 운영자에게는 그 이상이다. 클라우드를 도입시 고려해야 되는 상황과 시장 에 대해서 설명하고자 한다.
미국은 클라우드 전환 율이 5:5 이지만 한국은 이제 8:2 -> 7:3으로 넘어가고 있는 상황이다. 혹자는 낮은 클라우드 전환 율이 해외에 비해 경쟁력이 없다, 뒤쳐지고 있다 라는 이야기를 하고 있다.
엄격하게 말하면, 이러한 상황은 한국 시장의 특성때문에 그렇다. 미국,중국은 내국 서비스라고 해도 미국 전역에 서비스를 배포해야 한다. 개별 IDC 업체들을 돌아가며 IDC 특성에 맞추어가며 배포하는 것보다, AWS, Azure, GCE와 같은 글로벌 밴더사의 클라우드 플랫폼에서 운영 배포하는 것이 유지보수가 훨씬 쉽기 때문에, 미국, 중국 전역 또는 글로벌한 서비스들은 클라우드로 빠르게 전환되고 있는 추세다.
현재 한국은 중견 기업 이상급들이 비용 절감을 위해 오픈 스택, Private Cloud 도입을 하고 있는 추세이다. 하지만 글로벌에 나갈때는 멀티 리전, 멀티 존에 대한 운영이나 경험들에 대해 부족해 어려움을 겪고 있는 현실이며, 이러한 경험을 가진 인력을 구하기는 쉽지 않다.
클라우드는 공유 제한

그림 1. 클라우드는 공유자원
개발자, 운영자 DBA가 클라우드가 가져오는 가장 큰 제약은 클라우드는 공유자원이라는 것이다. 하나의 머신에, 가상화된 여러개의 인스턴스를 올려 놓은 것이다. 즉 다시 말하자면, 우리는 공유자원을 빌려 쓰는 것이므로 오늘 잘 동작한다고 해서 내일 잘 동작한다는 것을 보장할수 없다.
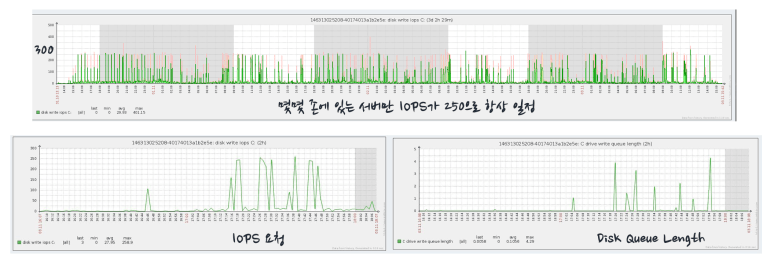
그림 2. 클라우드 장애의 단골 손님 – IOPS 부족 문제
국내 서비스중인 안정적인 게임이 중국에 클라우드에서 배포되고 나서 발생한 장애사례이다. 한국에서는 실제 물리서버에서 배포를 했었는데, 중국 진출 후 클라우드를 처음 도입하였다. 그런데 두개의 리전에 로그인 서비스를 배포 했는데, 특정 시간대에 한쪽 리전에서만 계속 로그인이 제대로 되지 않아 튕기는 문제가 발생했다.
장애시 개발팀은 이미 몇 년동안 검증된 로직인데, 원인을 찾기 힘들어 했었고, 문의가 들어와 확인을 해보니 클라우드 인프라의 문제였다. 바로 클라우드에 가장 장애로 많이 이어지는 IOPS (초당 발생하는 IO) 가 대표적인 예이다. 위 그림을 보면 IOPS가 초당 250으로 제한이 되어있는 것처럼 볼수 있으며, 실제 IOPS 요청에 비해 부하가 반영이 되지 않아 Write Queue에 요청이 쌓여 있는 것을 볼수 있다.
왜 이러한 현상이 발생했을까? 앞서 언급한 것 처럼 클라우드는 공유자원이다. 즉 하나의 Host 머신에서 우리 서비스 이외에 다른 서비스들도 입점 할수 있으며,이 서비스가 특정 시간마다 과도한 자원을 사용한다면 (IO가 많이 필요한 배치 작업을 돌린다면), 우리 서비스에 영향을 줄수 있다는 것이다. 그래서 기존 서비스를 쾌적한 다른 존으로 배치하고 나서 장애는 해결되었다.
클라우드의 도입시 고민해야 하는 것들
- DBA나 개발자가 처음 클라우드를 접할 때, 가장 간과하는 것이 클라우드와 물리 서버의 스펙 산정이다. 보수적으로 클라우드는 동일한 스펙의 물리 서버보다 40%~50% 수준의 성능을 감안해야 된다는 것이다.
- 각 인스턴스 별로 IO를 잘 분산해 비용 절감적인 아키텍처를 유지하는 것이 중요하다. (DB를 클라우드로 전환할 경우. DBMS 쿼리의 문제가 아닌, IOPS가 모잘라 Slow Query가 발생하는 경우도 종종있다.) 즉 IO를 잘 관리하는게 핵심이다. IO를 보장받는 AWS의 Provisioned IOPS, Azure의 Premium Storage 와 같은 제품을 판매하지만, 비용이 만만하지 않다.
- 메모리 비용도 1G당 월 1만원 정도의 비용이라, 로그 , 시계열 데이터 같은 경우 메모리를 많이 사용하는 RDBMS 보다는, Time Series (시계열) DB를 사용하여 비용을 아끼는 것이 중요하다.
어떠한 지표로 우리 시스템을 바라보아야할까?
리눅스에서 성능과 관련된 명령어들을 나열해 보면 다음과 같다.
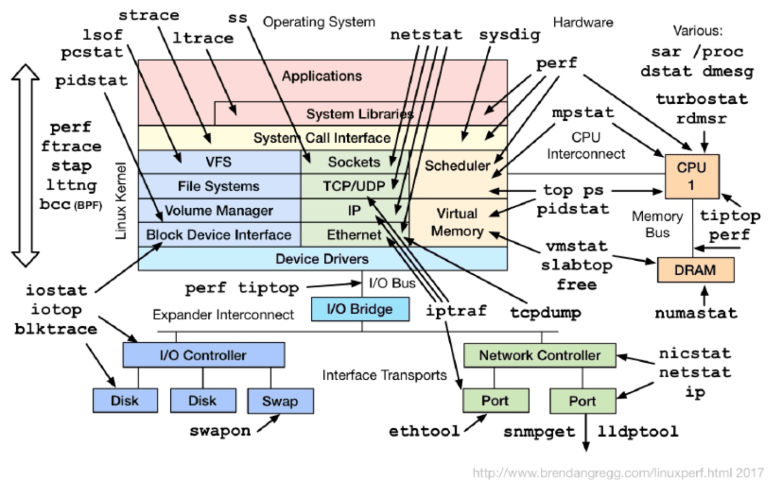
그림 3. 리눅스 성능 지표 (출처 – Brendan / Netflix Tech Blog )
이 많은 지표에서 우리는 무엇을 봐야 할까?
uptime dmesg | tail vmstat 1 mpstat -P ALL 1 pidstat 1 iostat -xz 1 free -m sar -n DEV 1 sar -n TCP,ETCP 1 top
Netflix에 기술 블로그에 60초안에 서버 성능 분석하기에서 추천한 지표이다. 상세한 설명은 링크를 보기 바라며, 기본 적인 설명이 잘 되어있다. 한 걸음 더 나아가서, 이러한 지표를 더 이해하기 쉽게 구성을 하면 어떨까?
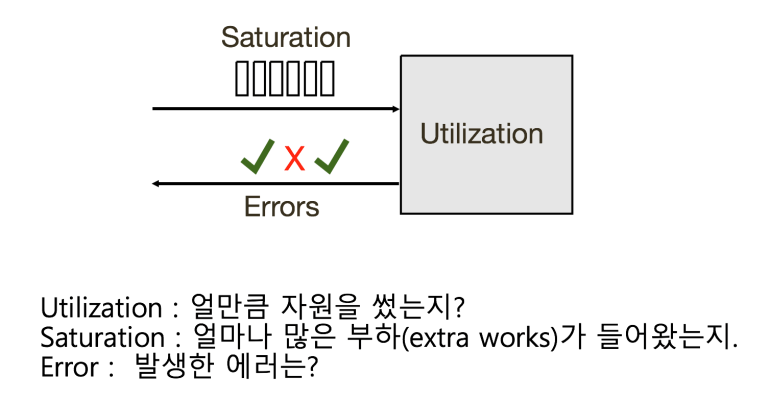
그림 4. USE 방법론 – 출처 Brendan의 성능 페이지
이러한 고민에 나온 지표들이 USE 메소드, TSA (쓰레드 상태로 보는 방법로도 이다. ) 메소드 이다. 이중에서 USE 메소드를 소개하고자 한다.
단순히 사용률(Utilization) 만 제공하기 보다는,
- 얼마나 많은 부하(Saturation)가 들어와서
- 이러한 사용률( Utilization)이 나왔는지 문제가 발생했다면
- 문제가 발생했다면 에러 메세지들은 무엇인지
본다면 한결 인과 관계를 파악하기 쉬워진다.
| Resource | Utilization | Saturation | Errors |
| CPU | mpstat-PALL1,
sumnon-idlefields |
vmstat1,”r” | perf |
| Memory
Capacity |
free–m,”used”/”total” | vmstat1,”si”+”so”;
demsg|grepkilled |
dmesg |
| StorageI/O | iostat–xz1,
“%util” |
iostat–xnz1,
“avgqu-sz”>1 |
/sys/…/ioerr_cnt;
smartctl |
| Network | nicstat,”%Util” | ifconfig,”overrunns”;
netstat–s”retrans…” |
ifconfig,
“errors” |
실제 USE 메소드의 한 예로 위와 같은 지표들을 선정할수 있다. 분류화가 되니 훨씬 이해하기 쉽다.
이외에도 추가적으로 봐야 되는 지표들
TCP 연결 상태

그림 5. TCP 연결 상태
자원 사용량은 여유가 있는데, 장애가 난 경우도 있다. 네트워크가 불안정하거나, 개발로직의 문제의 TCP Connection이 제대로 닫히지 되지 않아 CLOSE_WAIT가 쌓여서 발생한 경우이다.
CPU Steal Time
CPU Steal Time은 호스트 OS에서 우리 VM으로 까지 CPU를 할당할때 걸리는 시간이다. 평상시는 2ms 이하이며, 이 지표가 좋아지지 않는다면 Host OS나 다른 VM에서 과도하게 자원을 사용하는게 아닌지 의심해 볼만 하다.
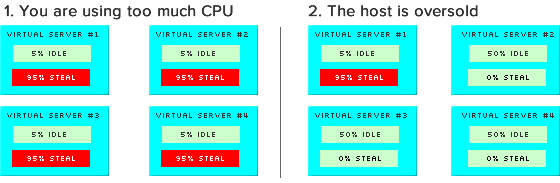
그림 6. CPU Steal 현상 – 출처 http://bit.ly/1w1HQy7
만약 동일한 역할을 하는 서버들이, (같은 호스트 OS가 아닌) 다른 존등에 흩어져 있는데 위와 같은 현상이 발생했다고 하자.
- 모든 인스턴스에서 CPU Steal Time이 증가한 경우 : 이 경우는 전역적으로 자원이 모자라다는 것을 의하며, 자원을 늘려야 되는 문제 된다.
- 특정 서버만 CPU Steal Time이 증가한 경우 : 이 경우는 하나의 VM에만 발생했다는 것은 해당 VM이 올라간 Physical 서버에 문제가 있을 확률이 높으며, 다른 존 또는 새롭게 인스턴스를 생성하여 이사갈 필요가 있다.
맺으며.
클라우드에 대한 이해, 부하 관리의 중요성, 알아야 할 필수적인 지표들을 소개해 드렸다. 다음 글에서는 Dropbox가 클라우드 환경에서 서비스의 품질을 지키기 위한 여러 노하우를 공유해 드리고자 한다.
