아키텍처 시각화 패턴 II
패턴 저자 : 손영수, 오혜성, 양현철, 정승수
아키텍쳐 시각화 패턴 I 회에서는 아키텍처 시각화 패턴의 전체적인 구조와 구성되는 패턴들의 종류들을 간단히 소개하고, 아키텍처 시각화를 하기 전에 소프트웨어 시스템을 분석하기 위한 기본 요소들인 Domain Level Classifier Pattern과 Class Dependency Classifier Pattern에 대해서 살펴보았다. 2회에서는 시간에는 소프트웨어 시스템의 아키텍처적인 분석에 기본이 되는 다양한 Metric 분석과 관련된 패턴에 대해서 설명하고자 한다
Base Metric Extractor Pattern의 정의
소프트웨어 시스템의 아키텍처를 분석하기 위하여 의존성만을 이용하게 되면 분석의 시야가 좁아 보다 다양한 측면에서의 분석이 힘들어진다. 그리고 의존성만을 시각화한 Chart로는 상호 참조와 같은 아키텍처적인 문제만을 바로 확인할 수 있고 그 외의 소스 코드의 크기나 복잡성 등과 관련된 문제들은 확인할 수 있는 방법이 존재 하지 않는다. 의존성 분석만으로는 파악할 수 있는 아키텍처적인 문제들의 한계가 존재한다. 그렇기 때문에 이를 보완할 수 있는 다른 분석 방법들이 필요하다. 또한 이를 보완할 분석 방법도 매우 직관적이고 명시적으로 분석할 수 있어야 하며, 매우 빠른 시간에 아키텍처를 파악할 수 있어야 한다.
이때 소프트웨어 메트릭이라는 소프트웨어 시스템의 품질을 나타내는 지표를 이용하면 이 문제를 해결할 수 있다. 이 지표는 소프트웨어의 측정 기술을 기반으로 소프트웨어 생명 주기 동안에 소프트웨어의 특징 또는 특성을 객관적이고 과학적인 수치로 정량화한 지표이다. 또한, 다양한 문제점들을 정의하고, 관련된 기초 데이터를 수집하고, 문제점들을 객관적이고 과학적인 수치에 의해 분석하여 다양한 문제점들의 연관 관계 및 해결 방법을 탐색하며, 다양한 문제점들을 종합적으로 해결할 수 있는 문제 분석 프로세스 및 소프트웨어에 대한 지표이다.
이러한 지표들 중에서 품질 향상에 많은 도움을 줄 수 있는 소프트웨어 메트릭의 종류를 크게 4가지가 존재한다.
- 첫번째로 단순히 패키지, 클래스, 메소드, 필드의 갯수, 코드 라인 수를 나타내는 “Count Metric”,
- 두번째로 코드내의 순환복잡도, 무거움, 엉킴을 나타내는 “Complexity Metric”,
- 세번째로 코드 간의 의존성을 나타내는 “Robert C. Martin Metric”,
- 마지막으로 코드간의 상속을 수치로 나타내는 “Chidamber & Kemerer Metric”
이러한 메트릭을 통해 다음과 같은 이점을 얻을수 있다.
- 소프트웨어 시스템의 코드를 정량적으로 분석이 가능하다.
- 소프트웨어 시스템의 품질을 수치화 시키기 때문에 객관적인 분석이 가능하다.
- 소프트웨어 시스템의 문제를 직관적으로 파악할 수 있다.
- 소프트웨어 시스템을 다양한 시각으로 분석할 수 있게 된다.
Base Metric Extractor Pattern의 세부패턴
Count Metric
“Count Metric”은 각각의 도메인에 해당하는 코드가 몇 개 있는지, 코드의 라인 수는 얼마나 되는지 나타낼 수 있다. “Count Metric”을 이용하여 소프트웨어의 전체적인 크기를 알 수있어 개발진행 정도를 파악 할 수 있다. Metric은 각 도메인 레벨에 따라 구하는 정보가 달라지거나 한정되어 있다. 그것을 아래의 표와 같이 나타내었다. 이 정보는 stan4j에서 가져왔다.

표 1. Count Metric
Complexity Metric
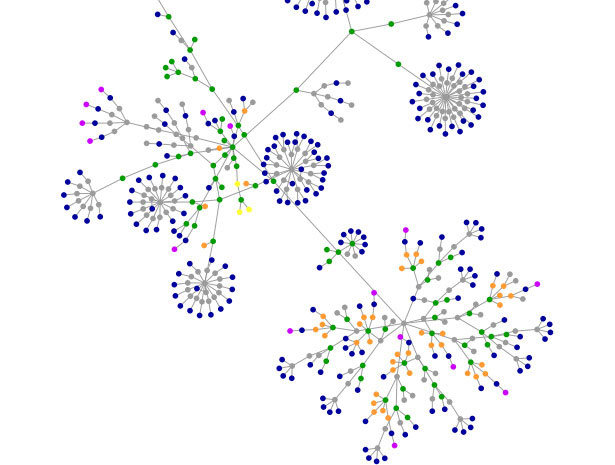
“Complexity Metric”은 아키텍쳐를 시각화하는데 가장 중요한 지표라 할 수 있다. 그 중 “Cyclomatic Complexity Metric” [Gill+91]은 코드 내에 얼마나 많은 분기문이 있는지를 나타낸다. 분기문이 많을수록 예외 경우가 많이 발생하는것을 의미하므로 복잡한 코드라고 할 수 있다. “Fat Metric”은 부모 도메인 안에 자식도메인들 끼리 의존성의 횟수를 의미한다. 자식도메인들 끼리 의존성이 많은 수록 부모도메인은 무겁다고 할 수 있다. 또한 “Tangled Metric”은 역참조를 파악할 수 있는 지표이다. 같은 도메인상의 노드 끼리 서로 참조를 한다면 이를 엉켜(Tangled)있다고 표현하고 서로의 변화가 서로에게 영향을 미치므로 좋지 않은 아키텍처라 할 수 있다.
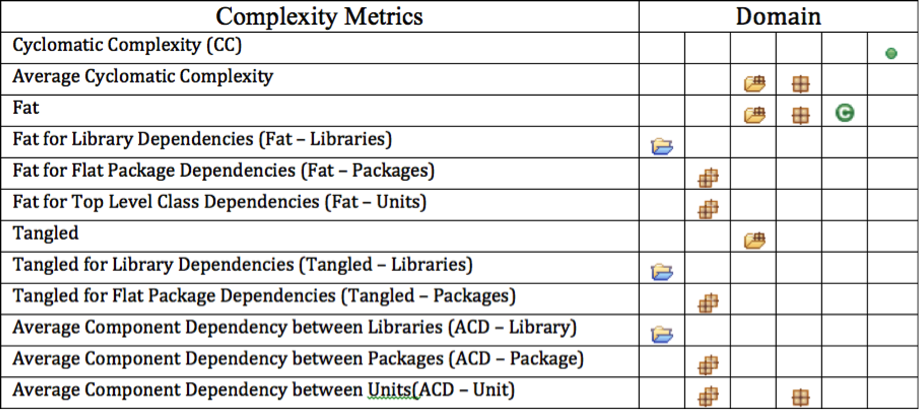
표 2. Complexity Metric
패키지 도메인에서, 패키지가 추상화가 잘되어 있는지 안되어있는지 쉽게 파악할 수 있게 해준다. 참조를 얼마나 하고 있는지 보여주는 “Afferent Coupling”, 참조를 얼마나 당하고 있는지 보여주는 “Efferent Coupling”, 추상화가 얼마나 되었나 보여주는 “추상화 정도”, 이러한 값들을 우선 계산하여 추상화가 필요한 패키지를 한눈에 볼 수 있는 Robert C. Martin 차트 (이 링크를 가시면 상세한 설명을 보실수 있습니다) 를 그릴 수 있도록 해준다. [Martin 00]

표 3. Robert C. Martin Metric
Chidamber & Kemerer Metric
이 지표는 클래스에만 관련된 지표로, 부모클래스의 갯수, 자식클래스의 갯수, 클래스 내의 필드, 메소드관의 의존성에 집중한 지표이다. 이 지표로 클래스의 오염도를 파악할 수 있다. [Hitz+96]
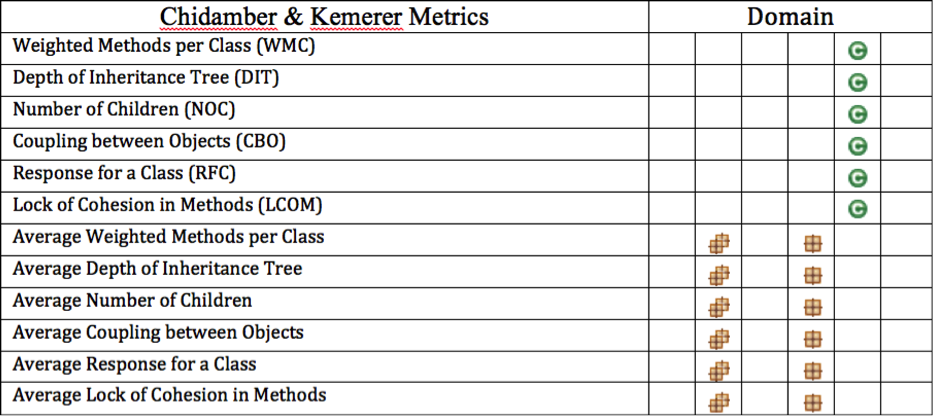
표 4. Chidamber Kemerer
Base Metric Extractor Pattern의 구현
“Base Metric Extractor” 패턴을 수행하기 위해선 우선적으로 저번에 소개한 “Domain Level Classifier” 패턴이 선행 되어 있어야 한다. 객체지향 언어를 도메인으로 나누고 각각의 도메인에 맞는 코드의 지표를 구함으로써 소프트웨어 아키텍처 시각화를 더 일목요연하게 표현 할 수 있게 되는 것이다. 또한 도메인간의 의존성을 수치로 시각화 하기위해 “Class Dependency Classifier” 패턴도 선행되어야 한다.
“Base Metric Extractor”패턴을 구현하기 위해 위에서 정의했던 4가지 종류의 다양한 지표를 구해야한다. 우리는 이 지표들 중에 한 예로써 ACD(Average Component Depandancy)[Jungmayr 02] 지표에 대해서만 설명하고자 한다. (NIPA 소프트웨어 공학센터 연구 과제를 통해 추후 여러 지표에 대해 설명하겠다 – 국내 참고자료 소프트웨어 컴포넌트 재사용성 매트릭 )
ACD 모든 클래스 간의 의존성을 나타내는 지표이다. 예를들어 클래스A, 클래스B, 클래스C가 있을 때, 클래스A가 클래스B를 호출하고, 클래스B가 클래스C를 호출하면, 클래스A는, 클래스B, 클래스C와 의존성이 있는 것이고, 클래스B는 클래스C와 의존성이 있는것이다. 이러한 의존성의 평균을 표현한 것이다.

그림 1 – ACD의 일반적인 예제
기본 절차
- 1단계: 클래스간의 의존성을 그래프로 표현한다. ACD의 연산을 쉽게하기 위해 클래스를 그래프의 Node로, 의존성을 Edge로 표현한다.
- 2단계: 그래프에서 싸이클을 이루는 노드들을 의미상 하나의 노드로 변환한다.
- 3단계: 트리 그래프에서 Leaf 노드를 구한다.
- 4단계: 새로 생성된 Leaf노드의 CD값은, 노드가 호출하는 이미 제외된 Leaf노드의 CD값의 합으로 구한다.
- 5단계: 하나의 노드로 묶었던 싸이클을 이루는 노드를 다시 풀어주어 모두 동일한 CD값을 적용시켜준다.
- 6단계: 모든노드의 CD값의 평균을 구한다.
절차 설명
1 단계: 클래스간의 의존성을 그래프로 표현한다. ACD의 연산을 쉽게하기 위해 클래스를 그래프의 Node로, 의존성을 Edge로 표현한다.

그림 2. 그래프로 표현된 클래스들의 의존성
2 단계: 그래프에서 싸이클을 이루는 노드들을 의미상 하나의 노드로 변환한다.
싸이클을 이루는 노드들을 우선적으로 구별해 주어, 추후 계산할 그래프탐색에서 중복탐색을 줄여 속도를 개선시킬 수 있기 때문이다. 이 결과로 그래프는 트리의 형태로 변환 된다.

그림 3. 싸이클을 구분한다
3 단계: 트리에서 Leaf 노드를 구한다.
Leaf노드는 다른 노드로 가는 Edge가 없기 때문에 CD(Component Dependency)값을 0으로 우선적으로 구할 수 있다. 그 후 Leaf노드를 그래프에서 제외시켜 새로운 Leaf노드들을 생성한다.
그림 4. Leaf 노드 제외
4단계: 새로 생성된 Leaf노드의 CD값은, 노드가 호출하는 이미 제외된 Leaf노드의 CD값의 합으로 구한다.
이 때 자식 중에 2단계에서 적용했던 싸이클을 이루는 노드들을 호출한다면 CD값에 싸이클을 이루는 노드의 갯수까지 더해주어야한다. 그 후 Leaf노드를 그래프에서 제외시켜 새로운 Leaf노드들을 생성한다.
이러한 과정을, 모든 노드가 제외될때까지 반복한다.

그림 5. 노드의 값들의 변경 진행
5단계: 하나의 노드로 묶었던 싸이클을 이루는 노드를 다시 풀어주어 모두 동일한 CD값을 적용시켜준다.

그림 6. 싸이클을 이루는 노드를 다시 추가
6단계: 모든노드의 CD값의 평균을 구한다.
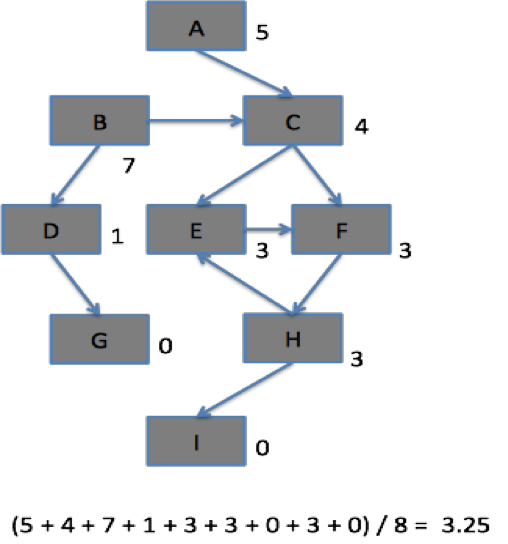
그림 7. 싸이클을 이루는 노드의 값 갱신
이렇게 Base Metric Extractor Pattern에 구현 과정에 대하여 간단히 이야기 설명하였다. 이 패턴을 구현하게 되면 소프트웨어 시스템의 품질을 평가하기 위한 기초 자료를 모두 수집하게 되며, 이 자료를 바탕으로 소프트웨어의 오염도를 매길수 있게 된다.. 그리고 이 패턴은 대부분의 소프트웨어의 품질을 분석을 지원해주는 STAN4J, Structure101 등의 툴들에서도 이와 유사한 방법들을 이용해 소프트웨어 시스템의 오염도를 추출하여 의존성을 시각화 해준다.
Dependency Chart Pattern의 정의
소프트웨어 시스템의 속하는 다양한 도메인들의 의존성(상속, 참조 등)은 소프트웨어 시스템의 심각한 아키텍처적인 문제점이나 전체적인 그림을 그려볼 수 있도록 도와주는 아키텍처 분석에 있어서 중요한 정보이다. 그렇기 때문에 앞서 소개하였던 클래스 다이어그램을 통한 분석이나 소스 코드를 통한 분석에서도 이러한 도메인들 간의 의존성을 파악하는 부분에 많은 비중을 두고 분석하게 된다. 그 중에서도 특히 클래스 다이어그램을 통한 분석은 대부분이 이러한 의존성을 중심으로 아키텍처를 파악한다고 할 수 있다. 하지만 클래스 다이어그램을 통한 분석은 너무 넓게 바라보기 때문에 분석으로 얻을 수 있는 정보가 너무 적으며, 소스 코드를 통한 분석은 너무 깊게 바라보기 때문에 분석에 많은 시간이 걸리며 전반적인 아키텍처에 대한 큰 그림을 파악하기 힘들다.
- 아키텍처적인 문제점을 발견하기에 많은 시간이 필요한 클래스 다이어그램과 코드 분석 방법
클래스 다이어그램과 코드를 바탕으로 도메인간의 의존성을 분석하게 되면 소프트웨어 시스템에 내제 되어있는 상호 참조와 같은 다양한 아키텍처적인 문제점들이 바로 코드나 클래스 다이어그램에는 들어나지 않아 문제를 발견하기가 매우 어렵다.
- 소프트웨어 시스템의 아키텍처를 가늠하기 힘든 클래스 다이어그램과 코드 분석 방법
이러한 분석 방법으로는 소프트웨어 시스템의 전체적인 흐름과 아키텍처를 파악하기에는 무리가 있다. 이는 클래스 다이어그램의 경우에는 단순히 의존성만이 나타나고, 그 의존성이 발생하는 부분이나 발생 정도에 대한 내용들을 제공해주지 않으며, 코드 수준에서는 아무런 기본 정보를 제공해주지 않기 때문에 분석자가 스스로 파악해야만 한다.
위와 같은 문제점을 해결하기위해 소프트웨어 시스템 내의 의존성 정보들을 이용하여 시각화하면 분석자에게 보다 많은 정보를 줄 수 있게 된다. 의존성을 바탕으로 시각화를 하계 되면 우선 클래스 다이어그램의 기본적인 상속이나 추상화 수준 등에 정보는 기본적으로 포함하게 된다, 이 외에도 현재 소프트웨어 시스템의 전체적인 흐름을 파악할 수 있게 되고, 소프트웨어 시스템이 내부적으로 가지고 있는 크기 문제나 상호 참조와 같은 아키텍처적인 문제점을 매우 쉽게 발견 할 수 있다.
|
클래스 다이어그램 레벨 |
코드 레벨 |
의존성 레벨 |
|
|
분석할 수 있는 의존성 |
클레스 도메인에서의 상속 및 접근 의존성 |
소프트웨어 시스템 안에 존재하는 모든 의존성 |
소프트웨어 시스템 안에 존재하는 모든 의존성 |
|
분석 해야 할 대상 |
클래스 다이어그램 |
실제 코드 전체 |
소프트웨어 시스템 안의 의존성 정보 |
|
직관적으로 얻을 수 있는 아키텍처 정보 |
대략적인 의존성 및 구성 정보 |
없음 |
실제 소프트웨어 시스템의 의존성 및 구성 정보 |
|
직관적으로 확인할 수 있는 아키텍처적인 문제점 |
추상화 수준 |
없음 |
상호 창조, 추상화 수준 |
표 5 – 각 분석 방법의 비교
Dependency Chart Pattern을 이용하여 소프트웨어 시스템을 적절한 범위 내에서 분석할 수 있게 된고, 소프트웨어 시스템의 아키텍처를 보다 빠른 시간 안에 파악할 수 있게 된다. 또한 소프트웨어 시스템의 아키텍처적인 문제점들을 파악하기 쉬워지게 된다.
Dependency Chart Pattern의 세부 패턴으로 Dependency Structure Matrix Pattern, Dependency Composition Digraph Pattern이 있으며 두 패턴에대한 자세한 내용은 다음시간에 정리하도록 하겠다.
정리
이번 시간에는 아키텍처 시각화를 하기 전에 소프트웨어 시스템을 분석하기 위한 기본 요소 Base Matric Extractor Pattern과 Dependency Chart Pattern에 대하 알아보았다. 다음 시간에는 Dependency Chart Patten의 세부패턴을 살펴보고, 소프트웨어 시스템의 아키텍처를 시각화 하기 위한 패턴들에 대해서 설명하고자 한다.

[…] 아키텍처 시각화 패턴 I 아키텍처 시각화 패턴 II […]