아키텍처 시각화 패턴 I
패턴 저자 : 손영수, 오혜성, 양현철, 정승수

소프트웨어 시스템에 있어서 아키텍처는 소프트웨어의 개발이 진행 되면서 지속적으로 성장해 나가며, 고객의 다양한 요구 사항들을 수용할 수 있도록 변화에 대응할 수 있어야만 한다. 높은 품질을 가지는 소프트웨어 시스템을 개발하기 위해서는 계속 진화하는 소프트웨어 시스템의 아키텍처를 실시간으로 확인할 수 있어야 한다. 그러나 현재 알려진 기본적인 방법들로는 이러한 아키텍처 파악이 매우 힘든 것이 현실이다. 그래서 이번에는 소프트웨어 시스템의 아키텍처를 시각화 할 수 있는 다양한 방법들을 패턴으로서 이야기 하고자 한다.
소프트웨어 시스템의 아키텍처는 다양한 사람들이 참여하여 개발하게 되면 처음 의도와는 다른 방향으로 바뀌어질 가능성이 존재하며, 이에 따라서 원치 않았던 잠재적인 아키텍처의 문제들이 발생하거나 추후 확장 가능한 유연한 아키텍처에서 멀어지는 상황이 발생하게 된다. 이러한 상황을 방지하려면 개발을 진행하고 있는 소프트웨어 시스템의 아키텍처를 자주 살펴보고 문제가 발생될 수 있는 부분들을 개선해나가야만 한다.
이러한 소프트웨어 시스템의 아키텍처를 파악하기 위한 방법들은 일반적으로 클래스 다이어그램을 분석하거나 소스 코드를 분석하여 파악하는 방법들이 존재한다. 그러나 이러한 방법들은 여러 단점들을 가지고 있는데 클래스 다이어그램을 기반으로 분석하는 방법의 경우 너무 넓은 시점에서 소프트웨어 시스템을 분석하기 때문에 정확한 아키텍처를 파악하기도 힘들며, 아키텍처적인 문제들을 해결하기에는 너무 적은 정보를 제공한다. 그리고 코드 기반 분석은 클래스 다이어그램 기반 분석과는 달리 너무 작은 시점에서 소프트웨어 시스템을 분석하기 때문에 아키텍처를 파악하는 것이 힘들고, 분석하는 것도 너무 많은 시간이 걸리게 된다. 이렇게 기존의 쉽게 접할 수 있는 방법들로는 소프트웨어 시스템의 아키텍처를 파악하기란 매우 어렵다고 할 수 있다.
그래서 여기에서는 소프트웨어 시스템의 아키텍처를 보다 간편하게 분석할 수 있도록 도와주는 아키텍처 시각화 기법들을 패턴으로써 정리하여, 해당 시각화들을 구현하기 위한 기본적인 방법들을 소개하고, 각각의 시각화 패턴을 활용한 분석들의 장점과 단점들을 소개할 것이다.
아키텍처 시각화 패턴을 위한 로드 맵
앞서 이야기 했던 아키텍처 분석 방법들은 소프트웨어 시스템을 너무 넓은 범위에서 보거나, 너무 좁은 범위에서만 보기 때문에 다양한 문제들이 발생 하였다. 그렇기 때문에 적절한 수준에서 소프트웨어 시스템을 바라보게 되면, 앞서 이야기했던 방법들에서는 찾을 수 없었던 문제점들을 바로 확인할 수 있게 된다. 이러한 적절한 수준으로 사용할 수 있는 분석 방법은 바로 소프트웨어 시스템의 다양한 Metric 정보(소프트웨어 시스템에 대한 아키텍처적인 수치 정보)와 구성요소(도메인)들의 의존성을 분석하는 것이다. 이 방법을 이용하게 되면 소프트웨어 시스템의 아키텍처에 대한 정보들과 여러 문제점들을 다양한 수치 정보로서 바로 파악할 수 있게 되며, 의존성 분석을 통해 얻은 정보로는 실제 소프트웨어 시스템의 아키텍처적인 의존성을 보여주기 때문에 아키텍처 분석이 더욱 용이해지고, 상호 참조와 같은 아키텍처적인 문제점을 찾기에 용이해진다.
하지만 이러한 Metric 정보와 소프트웨어 시스템의 도메인들의 의존성을 분석하기만 하여서는 직관적이고 명시적인 분석결과를 얻을 수 없으며, 전체적인 분석 또한 빠른 시간 안에 할 수 없다. 그렇기 때문에 이러한 문제들을 해결하기 위해서는 Metric 정보와 도메인들의 의존성을 분석 정보들을 단순히 제공하는 것이 아닌 정보들을 시각화하여 분석 하고자 하는 사람이 쉽게 이해할 수 있는 다양한 Chart를 활용하는 형태로 분석 결과를 제공 해야만 한다.
이러한 아키텍처 시각화 기법을 사용하게 되면 코드 분석이나 클래스 다이어그램 분석에 비하여, 초기 비용(시각화 환경 구성 등)이 많이 필요하지만, 소프트웨어 시스템의 아키텍처를 보다 빠르게 분석할 수 있게 되며 잠재적인 아키텍처적인 문제점들을 미리 예방할 수 있도록 도와주며, 더 나아가 아키텍처를 확장 가능한 아키텍처로 유지할 수 있도록 도와주어, 고객의 요구 사항에 쉽게 대응할 수 있도록 해주게 된다.
이러한 형태로 아키텍처 시각화를 구축하기 위해서는 다음과 같이 패턴들을 적용해야 한다.
- 가) Domain Level Classifier 패턴을 기반으로 소프트웨어 시스템의 도메인들을 분류한다.
- 나) Class Relationship Classifier 패턴을 기반으로 분류된 도메인들 간의 객체 지향적인 의존성들을 모두 분류한다.
- 다) 분류된 도메인들과 객체 지향적인 의존성들을 정보들을 바탕으로 Base Metric Extractor 패턴을 활용하여 소프트웨어 시스템의 품질에 관한 Metric 정보들을 추출한다.
- 라) 구성된 Metric 정보와 의존성 정보들을 바탕으로 아키텍처 시각화(Dependency Chart 패턴, Size of Component Chart 패턴, Robert C Martin Chart 패턴, Pollution Chart 패턴)를 표현한다.

그림1. 소프트웨어 시각화를 위한 패턴언어
<그림 1>은 위에서 소개한 절차를 바탕으로 아키텍처 시각화 패턴을 구성하는 다양한 패턴들간의 관계들을 표현한 패턴 구성도(패턴 맵)이다. 앞으로 시각화 패턴을 구축하는 하위 패턴들부터 시작하여, 구체적인 아키텍처 시각화 방법들이 담긴 패턴들을 소개하는 일종의 하향식 접근을 통해 아키텍처 시각화 패턴에 대해서 이야기 하겠다. 추가적으로 여기에서는 설명을 보다 쉽게 하기 위해서 객체 지향 언어 중 Java을 기반으로 예제들을 설명하겠다.
Domain Level Classifier 패턴의 정의
소프트웨어 시스템의 아키텍처를 시각화하기 위해서는 제일 먼저 객체지향언어로 작성된 코드를 분석하고자 한다. 소프트웨어 시스템의 소스 코드는 MECE(Mutually Exclusive and Collectively Exhaustive)이라는 대 전제 하에 기반으로 작성되어있다. MECE란 항목들이 상호 배타적이면서 모였을 때는 완전히 전체를 이루는 것을 의미한다. 이를 태면 소스코드에서 필드와 메소드가 서로 겹치지 않고, 모였을 때는 클래스를 이루고, 또한 클래스들은 서로 겹치지 않고 모였을 때 패키지를 이루게 된다. 이렇게 객체 지향 언어에서는 다양한 도메인들을 가지고 있어 아키텍처 분석을 너무 세분화된 단위(Ex: 메소드, 필드)로만 처리하면 의존성, Metric들을 계산 하더라도 그 결과는 사용자가 보기에 너무 복잡하다. 예를 들면 아래 <그림 2>와 같이 의존성을 알아보기 힘들어질 정도로 매우 복잡해진 모습을 볼 수 있다.
그림 2 – 소스 코드의 최소 단위 분석 결과
반대로 세분화 시키지 않고 분석하게 되면, 사용자에게 보여줄 수 있는 정보가 매우 적어진다. 그렇기 때문에 사람들이 인지할 수 있는 적절한 레벨로 도메인을 나누어야 할 필요성이 있다. 그렇기 때문에 소스 코드 안의 객체 지향적인 정보들을 적절한 레벨의 도메인으로 나누어 정형화시킬 필요가 있다.
이때 소스코드의 도메인을 잡는 기준은 누구나 보아도 쉽게 이해 할 수 있는 단위 어야 한다. 소프트웨어 시스템의 소스코드는 MECE원칙을 기본으로 하여 구분되는 단위로 작성되어있기 때문에 도메인의 기준은 소스코드에 내포되어있다. 이러한 소스코드에 내포된 도메인 기준을 사람들이 이해할 수 있는 단위로 그대로 사용한다. 객체지향언어의 한 종류인 JAVA를 예로 들면 Method, Class, Package, Package Set, Project, Workspace 6개의 도메인으로 나누도록 한다. 또한 나눠진 각각의 도메인들은 Tree 구조로 나타낼 수 있다.
- Method & Field: Class를 이루는 구성 요소들이다. Field는 Class 내에서 사용 되는 변수들이고 Method는 클래스에서 사용하는 함수들이다.
- Class: 의존성 분석에 있어서 가장 기본이 되는 단위로 Method 와 Field 가 모여서 SRP(Single Responsibility Principle)의 원칙을 따르는 하나의 일을 하는 단위이다.
- Package: 연관된 Class들이 모여서 서로 상호 작용하여 복합적인 요구사항을 처리한다.
- Package Set : 연관된 Package들 끼리 모여 작은 서브 시스템을 이룬다.
- Project: Workspace의 일부로 소프트웨어 시스템에서 각각의 역할을 맡은 컴파일 되는 단위의 서브 시스템이다.
- Workspace: 소프트웨어 시스템으로 완전한 하나의 소프트웨어를 뜻한다.
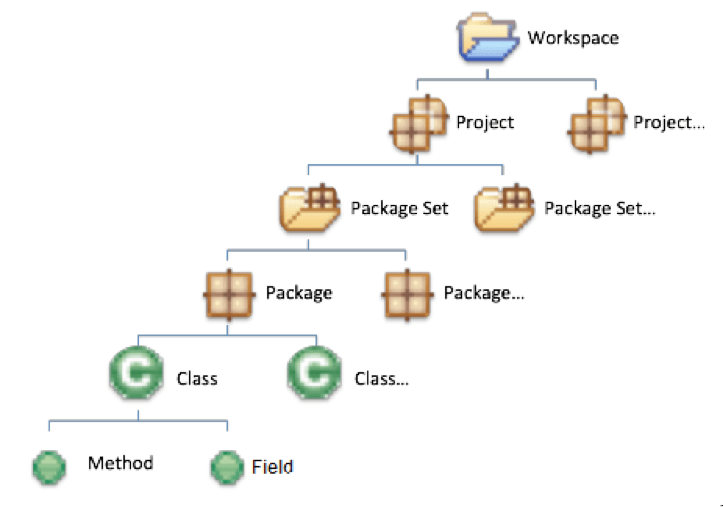
그림 3 – 도메인 레벨
이렇게 도메인을 나누면 코드를 단계별로 분석할 수 있게 되며, 사용자는 적절한 단계의 분석결과를 볼 수 있어 직관적인 이해가 가능하게 된다.
Domain Level Classifier 패턴의 구현
위에서 소개한 Domain Level Classifier Pattern을 구현하기 위해서는 다음과 같은 방법을 이용하여 구현해볼 수 있다.
package ABC;
class A
{
int B;
void C(void)
{
int D;
}
}
1 단계: 소스코드를 의미단위로 나누기 위해 추상 구문 트리(AST)로 변환한다. 추상 구문 트리는 소스 코드 의미 단위로 나누어 노드로 나타낸 트리이다. 앞에서 언급하였던 예제 소스 코드를 추상 구문 트리로 변환한다면 다음의 그림 4와 같다.
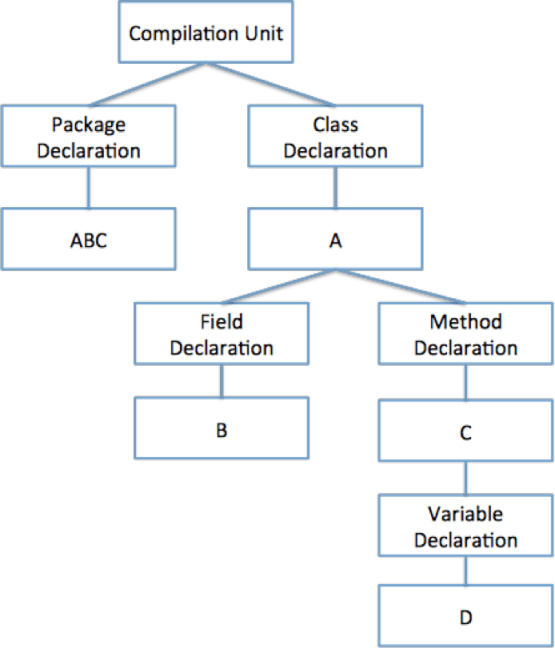
그림 4 – 변화된 추상 구문 트리
2 단계: Top-down방식으로 클래스, 메소드 도메인을 구한다.
소스 코드파일을 추상 구문 트리로 변환하였기 때문에 클래스가 추상 구문 트리의 상위 노드에 해당한다. 따라서 트리 구조 상 패키지 도메인이 가장 먼저 구해지며 다음으로 클래스, 메소드 도메인을 구한다.
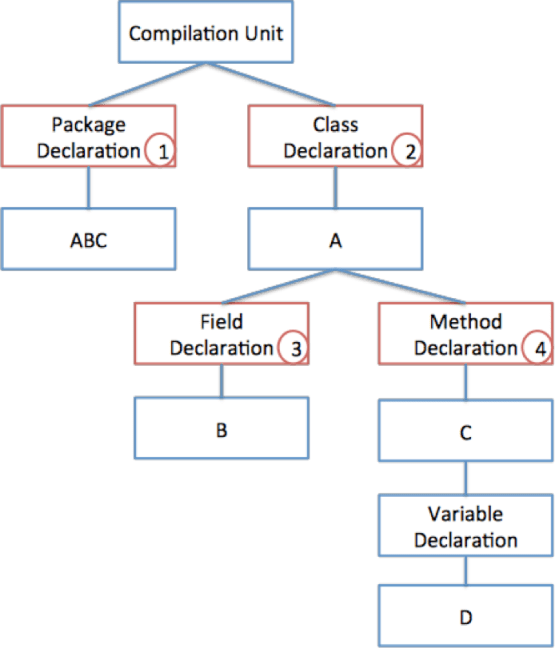
그림 5 – TopDown 방식으로 도메인을 분류
3 단계: 반면 패키지묶음, Project, WorkSpace 도메인은 Bottom-up방식으로 구한다.
하나의 추상 구문 트리 탐색이 끝날 때마다 클래스 도메인의 패키지 정보, 서브 시스템 정보를 이용하여, 부모 도메인을 구한다. 이러한 방식으로 도메인이 구해지는 이유는, 추상 구문 트리가 코드파일을 단위로 만들어지기 때문이다.
이렇게 Domain Level Classifier Pattern을 구현 과정까지 설명하였는데, 이렇게 이 패턴을 사용하게 되면 도메인을 나누어 객체 지향 언어를 단계 별로 분석할 수 있게 되며, 도메인을 사람들이 이해할 수 있는 단위로 그대로 나누어 아키텍처를 직관적으로 이해할 수 있게 된다.
그리고 이 패턴은 실제로 Structure101이라는 아키텍처 시각화 툴에서 의존성 분석(Dependency)을 해주는데, 이 툴에서는 분석할 Domain Level Classifier Pattern 패턴을 적용하여 분석자가 쉽게 인지할 수 있도록 도메인레벨을 나누어서 아키텍처를 시각화 해준다.
Class Dependency Classifier 패턴의 정의
Domain Level Classifier 패턴에서 구성되는 각각의 도메인들은 서로 간의 확실한 경계를 가지고 상호 배타적이다. 도메인끼리 서로 아무 의존성이 없으면 소프트웨어 시스템을 구성하는 것은 불가능하다. 그래서 도메인끼리 서로 간의 의존성을 가지고 있고 이러한 의존성과 도메인이 모여서 하나의 서브시스템을 이룬다. 이처럼 도메인 사이의 의존성은 서로 다른 경계를 가진 도메인을 이어 하나의 서브시스템이 되게 해준다. 그렇기 때문에 소프트웨어 시스템의 아키텍처를 파악하기 위해서는 도메인들 사이의 정확한 의존성을 파악할 수 있어야 한다. 그러나 Domain Level Classifier 패턴은 단순히 도메인들을 정의하여 분류만 해준다. 그렇기 때문에 각각의 도메인들의 의존성과 관련된 정보들을 포함되지 않아 정확한 아키텍처를 분석하는데 어려움이 있다.
그래서 이 패턴에서는 소프트웨어 시스템에 존재하는 각 도메인 간의 모든 의존성을 파악하고 정의 해야만 하며, 소프트웨어 시스템 안에서 발생하는 서로 간의 상속, 포함 등을 모두 정확히 파악 해야 한다. 그리고 소프트웨어 시스템은 Class 도메인의 하위 도메인 사이의 의존성을 정의하면 상위 도메인들은 하위 도메인들의 의존성을 기반으로 구성되기 때문에 모든 의존성을 파악 할 수 있게 된다. 또한 명확한 의존성을 파악하기 위해서는 도메인 사이의 의존성 사이에서 Source와 Target을 정확히 알아야 하고 어느 레벨의 도메인인지 정확히 파악해야 의존성을 제대로 정의 할 수 있게 된다. 대략적으로 소프트웨어 시스템의 의존성은 다음과 같은 기본 분류 기준에 따라서 분류된다.
- 의존성은 Source 도메인에서 Target 도메인 사이에서 정의된다.
- 객체 지향 언어에서 사용되는 다양한 관계(상속, 참조 등)를 기반으로 분류한다.
- 상위 도메인은 하위 도메인의 의존성을 기반으로 구축되어야 한다.
Class Dependency Classifier 패턴의 구현
위에서 소개한 Class Dependency Classifier 패턴을 구현하기 위해서는 다음과 같은 방법을 이용하여 구현해볼 수 있다.
1 단계: Domain Level Classifier 패턴을 구현한다. 이 패턴은 도메인간의 의존성을 정의하는 패턴이다. 우선적으로 모든 도메인들이 정의되어 있어야 각각의 의존성을 명확히 구현 할 수 있다.
2 단계: Class 도메인 및 하위 도메인 사이의 모든 의존성을 정의한다. 여러 가지 언어에서 모든 종류의 의존성을 정의할 수 있지만 객체 지향 언어중 JAVA에서 어떻게 의존성들을 정의 했는지 아래의 표와 같이 정의하였다.
| Source | Dependency Kind | Target | Description |
| Class | Extends | Class | Source 타입이 Target을 Extends/Implement 한 경우 |
| Class | Contains | Class | Source 타입에 Target 타입인 중첩 클래스를 포함하는 경우 |
| Class | Contains | Field | Source가 Targer을 포함하는 경우 |
| Method | Returns | Class | Source 메소드가 Target 반환을 선언한 경우 |
| Method | Has param | Class | Source 메소드가 Target 을 매개 변수로 선언한 경우 |
| Method | Throws | Class | Source 메소드의 예외 절에서 Target을 선언한 경우 |
| Method | Calls | Method | Source 메소드에서 Target 메소드를 호출한 경우 |
| Method | Accesses | Field | Source 메소드 Code에서 target 필드를 접근할 경우 |
| Field | is of type | Class | Source 필드의 타입이 Target 인 경우 |
| Any | References | Class | 아래에 포함되지 않는 모든 관계를 의미한다. – generic 형식의 매개 변수/ 범위 – 호출되는 메소드의 메개 변수/반환 타입 – 로컬 변수 타입 – catch 블록에 정의된 변수 타입 – instanceof 연사자에서 사용된 타입 |
3 단계: 소스코드 및 목적코드에서 2번에서 정의한 의존성을 추출 한다.
3 – 1: 이미 한번 컴파일된 목적 코드가 있는 경우
이미 한번 컴파일된 목적코드로 손쉽게 구현하는 방법이 있다. 이는 모든 도메인 이름이 정확히 목적 코드 안에 명시되 있으므로 매우 손쉽게 도메인들이 어떤 의존성을 이루고 있는지 알 수 있다. 하지만 한번 컴파일 된 코드를 가지고 구현하는 것이기 때문에 구현하고 나서 사용하기에 IDE와 연계되어서 사용하거나 JAR처럼 라이브러리 형태만 분석할 수 있는 단점이 있다.
3 – 2: 소스코드만 존재하는 경우
소스코드에서 의존성을 구하는 것이다. 소스코드에서 구현되기 때문에 목적코드 분석보다 범용성이 늘어난다. 소스코드만 제공하면 분석이 가능하기 때문에 IDE와 연계할 필요가 없어서 제약사항이 줄어들게 된다. 하지만 단점으로 소스코드에서 의존성을 추출하는 것 자체가 이미 컴파일 된 목적코드에서 뽑아내는 것보다 힘들고 외부 라이브러리가 포함된 프로젝트는 완벽한 분석이 불가능 하다.
구현 할 때 단순히 코드를 파싱 하는 형태로 구현하면 이름이 중복되거나 줄줄이 호출하는 형태의 소스 코드는 정확한 의존성을 표현하기가 힘들다. 그래서 소스 코드를 추상 구문 트리(Abstract Syntax Tree)로 변경하여 구현하는 편이 훨씬 편리하게 도메인들의 의존성을 구할 수 있다. 추상 구문 트리(이하 AST)는 각 구문에 따라서 Tree의 형태로 표현하는 것이다.
예를 들어 아래의 그림은 자바의 소스코드를 AST의 형태로 표현한 것이다.
public void PrintLog (Level level, String log)
{
m_LogManager.PrintLog(level,log);
}
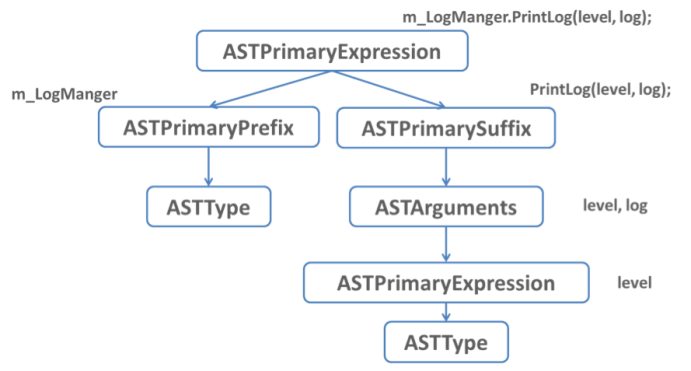
그림 8 – 구성된 AST
위의 그림과 같이 AST로 소스코드를 변환하게 된다면 void PrintLog() 함수 내부에서 m_LogManager의 타입을 찾아 어떤 함수를 호출 하였는지 쉽게 파악 할 수 있다. 그리고 처리 속도도 늘어 나게 된다. 분석할 필요가 없는 것들을 가지를 쳐내게 된다면 모든 소스코드를 분석해야 하는 것보다 훨씬 빠른 속도로 처리할 수 있다.
4 단계: 추출한 의존성을 표에서 정했던 템플릿으로 기록한다
위에서 추출한 의존성을 Source – Relationship – Target의 형태로 기록한다. 여러가지 방법이 존재하는데 일단 도메인 사이를 이어주는 Edge의 형태로 기록하여도 되고 따로 List를 생성해서 기록하여도 상관 없다. 하지만 각 Source와 Target의 도메인은 정확히 분별 할 수 있도록 기록하여야 한다.
이렇게 Class Dependency Classifier Pattern에 구현 과정에 대하여 간단히 이야기 설명하였다. 이렇게 이 패턴을 구현하게 되면 소프트웨어 시스템의 의존성을 시각화하기 위한 기초 자료를 모두 수집하게 되며, 도메인간의 모든 의존성을 정의할 수 있게 된다. 그리고 이 패턴은 대부분의 의존성 분석을 지원해주는 STAN4J, Structure101 등의 아키텍처 툴들에서도 이와 유사한 방법들을 이용해 소프트웨어 시스템의 의존성을 추출하여 의존성을 시각화 해준다.
정리
이번 시간에는 아키텍처 시각화 패턴의 전체적인 구조와 구성되는 패턴들의 종류들을 간단히 소개하고, 아키텍처 시각화를 하기 전에 소프트웨어 시스템을 분석하기 위한 기본 요소들인 Domain Level Classifier Pattern과 Class Dependency Classifier Pattern에 대해서 살펴보았다. 다음 시간에는 소프트웨어 시스템의 아키텍처적인 분석에 기본이 되는 다양한 Metric 분석과 관련된 패턴과 시각화 패턴들에 대해서 설명하고자 한다.
레퍼런스
- JArchitect(http://www.jarchitect.com/)
- STAN4J(http://stan4j.com/)
- D3(http://d3js.org/)
- Sonar(http://www.sonarsource.org/)
- [그림 2] JArchitect의 Dependency 분석화면
- [그림 6] STAN4J에서 Dependency정의한 표

총 4회이며, 한주마다 1회를 공개하겠습니다. 많은 분에게 도움이 되었으면 합니다.
기다리고 있습니다 ㅜ
기다려 주신다니 정말 감사하구요. 잘 다듬어서 올리겠습니다!!
좋은글 감사합니다. 코드분석으로 헤매다가 큰 도움을 얻고 갑니다
안녕하세요. 써 주신글 잘 읽었습니다. 궁금한 점이 있어, 질문 드립니다
3 – 2: 소스코드만 존재하는 경우
소스코드에서 의존성을 구하는 것이다. 소스코드에서 구현되기 때문에 목적코드 분석보다 범용성이 늘어난다.
-> 혹시 ‘범용성’이 어떤 측면의 범용성을 말씀하시는 건지 알 수 있을까요? 의존성 추출 외에 또 다른 분석 방법을 적용하기 쉽다 일까요? 아니면 빌드되지 않은 소스코드만 있으면 되니 더 간편하다는 의미일까요?
미리 답변 감사합니다 🙂
네 정확히 말씀 드리면 구문 트리로만 분석이 가능하기 때문에 더 쉬워진다는 말씀입니다. 목적 코드가 생각되면 그걸 역으로 꺼내는 리버싱 라이브러리를 써야 되기 때문이죠. 이때는 doxygen에서 사욯하는 것들을 이용했습니다. 답변이 늦어 죄송합니다.
[…] 아키텍처 시각화 패턴 I 아키텍처 시각화 패턴 II […]